HPC container runtime performance overhead: At first order, there is none
Torrez, Alfred, Reid Priedhorsky, and Timothy Randles. “HPC container runtime performance overhead: At first order, there is none.” (2020).
containters
- Charliecloud
- Shifter
- Singularity
environment
LANL’s CTS-1 clusters Grizzly (1490 nodes,
128 GiB RAM/node; HPCG) and Fog (32 nodes, 256 GiB RAM/node; SysBench, STREAM, and HPCG)
分别在三种容器以及裸机环境中进行测试。
benchmarks
SysBench
CPU性能。36路线程计算低于4000万的质数。
4个环境下耗时几乎相同。
STREAM
内存性能。编译选项 STREAM_ARRAY_SIZE=2,000,000 –cpu_bind=v,core,map_cpu:23。跑了100个单独的线程。
We compiled with STREAM_ARRAY_SIZE set to 2 billion to match the recommended 4× cache and pinned the process to a semi-arbitrary core using the Slurm argument –cpu_bind=v,core,map_cpu:23.
4个环境下测试出的带宽几乎相同
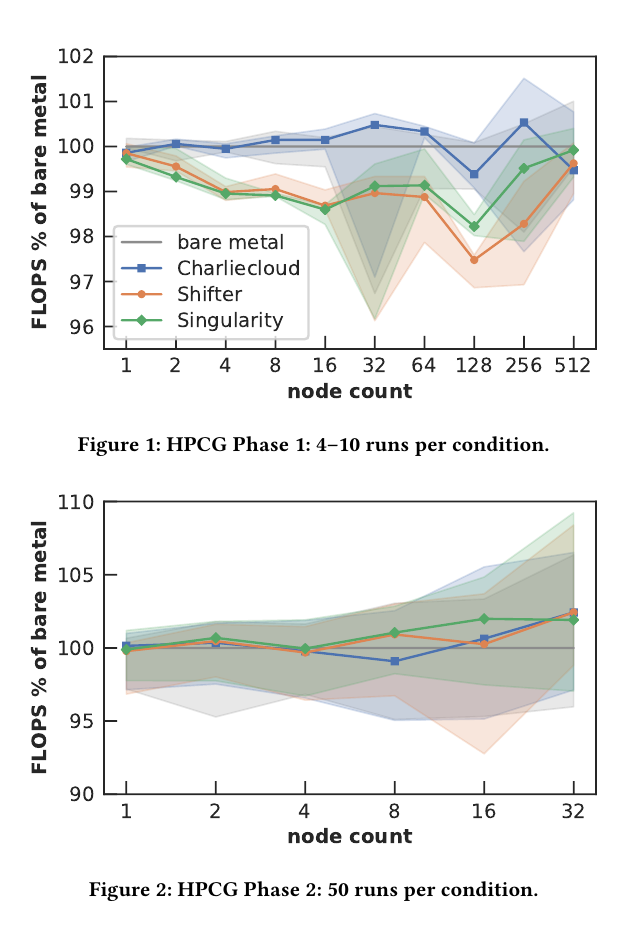
HPCG(High Performance Conjugate Gradients)
We used a cube dimension of 104 and a run time of 60 seconds, all 36 cores per node, one MPI rank per core, and one thread per rank.
memory usage
To understand node memory usage with STREAM, we computed MemTotal – MemFree from /proc/meminfo, sampled at 10-second intervals.
Bare metal total node usage was a median of 50.8 MiB. Charliecloud added 1200 MiB, Shifter 16 MiB, and Singularity 37 MiB.
Charliecloudn内存使用多可能是因为存储在tmpfs里的1.2Gib镜像。
For HPCG, we sampled at 10-second intervals the writeable/private field of pmap(1), which reports memory consumption of individual processes. Median memory usage for all three container technologies is, to two significant figures, 0.64% lower than bare metal at 1 node, 0.53% lower at 8 nodes, 0.53–0.54% lower at 64 nodes, and 1.2% higher at 512 nodes, a minimal difference.