A Tale of Two Systems: Using Containers to Deploy HPC Applications on Supercomputers and Clouds
Younge, Andrew J., et al. “A tale of two systems: Using containers to deploy HPC applications on supercomputers and clouds.” 2017 IEEE International Conference on Cloud Computing Technology and Science (CloudCom). IEEE, 2017.
container
- Docker
- Shifter
- Charliecloud
- Singularity
DevOps
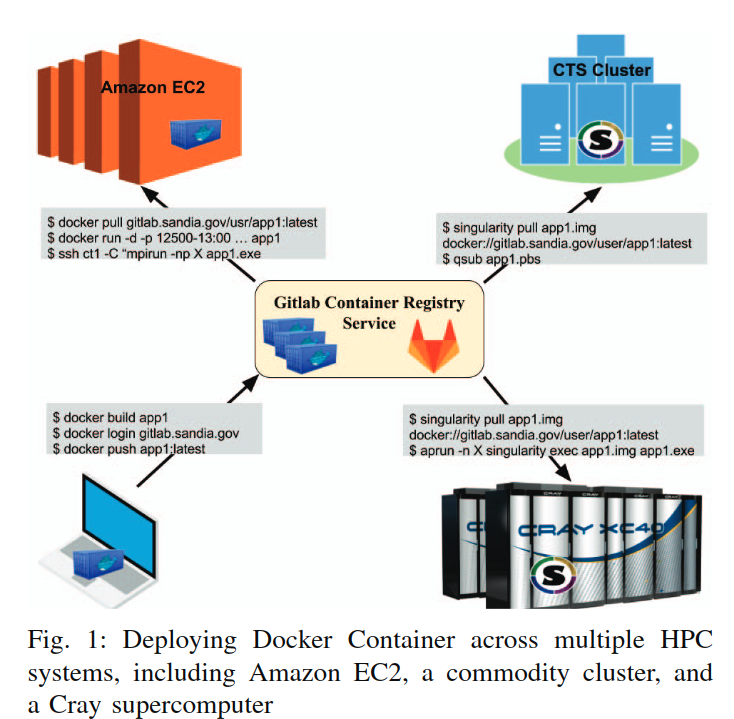
部署的工作流:
- 在本地电脑上使用docker容器(因为桌面电脑用win和macOS的比较多,docker都支持),将Dockerfile和项目代码保存到git项目中。
- 项目推送到远端的仓库,并将容器镜像放进容器注册服务。
- 在多个平台上(EC2、cluster、supercomputer)拉取代码,在容器中执行。
environment
镜像环境:
HPCG benchmark
Intel MPI Benchmark suite (IMB)
base image: Centos 7, both benchmarks were built using the Intel 2017 Parallel Studio, which includes the latest Intel compilers and Intel MPI library.
拉取镜像:
1
docker pull ajyounge/hpcg-container
Cray XC30 supercomputing platform
hardware:
Volta includes 56 compute nodes packaged in a single enclosure, with each node consisting of two Intel Ivy Bridge E5-2695v2 2.4 GHz processors (24 cores total), 64GB of memory, and a Cray Aries network interface.
shared file system
Shared file system supportis provided by NFS I/O servers projected to compute nodes via Cray’s proprietary DVS storage infrastructure.
OS:Cray Compute Node Linux (CNL ver. 5.2.UP04, 基于SUSE Linux 11), linux kernel v3.0.101
内核版本过老,需要做出修改才能使用Singularity。具体来说,增加了对loopback设备和EXT3文件系统的支持。config:
Specifically, we configure Singularity to mount /opt/cray, as well as /var/opt/cray for each container instance.
In order to leverage the Aries interconnect as well as advanced shared memory intra-node communication mechanisms, we dynamically link Cray’s MPI and associated libraries provided in /opt/cray directly within the container
链接的动态库包括:
- Cray’s uGNI messaging interface
- XPMEM shared memory subsystem
- Cray PMI runtime libraries
- uDREG registration cache
- application placement scheduler (ALPS)
- configure workload manager
- some Intel Parallel Studio libraries
Amazon EC2: c3.8xlarge
hardware:
- cpu: Intel Xeon “Ivy-Bridge” E5-2680 v2 (2.8 GHz, 8 cores, hyperthread) x 2
- memory: 60GB of RAM
- disk: 2x320 GB SSDs
- network: 10 Gb Ethernet network
OS: RHEL7
- config:
使用SR-IOV技术,加载了ixgbevf内核模块。
- config:
Docker: v1.19
benchmark
Benchmarks are reported as the average of 10 trials for IMB and 3 trials for HPCG, with negligible run-to-runvariance that is therefore not shown.
IMB
测试网络的带宽和延迟,对应MPI节点通信的性能。对于全静态链接和动态链接的版本做了测试。
PingPong bandwidth
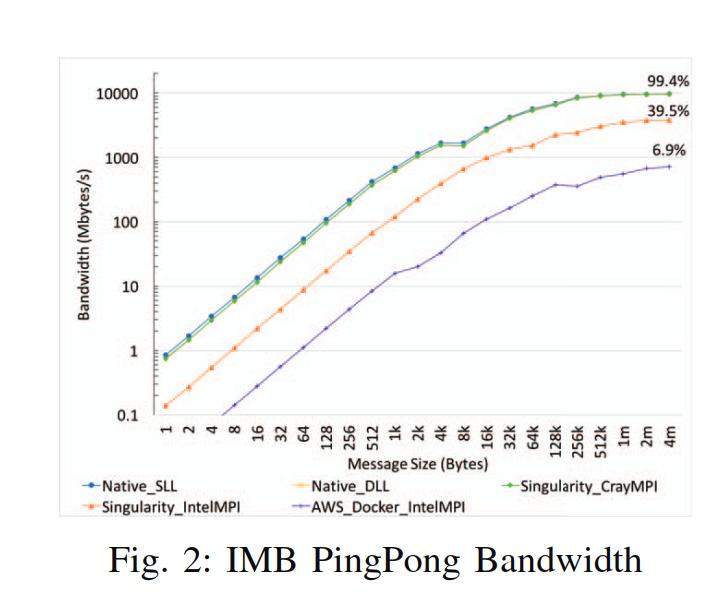
Singularity容器中链接CrayMPI,带宽最高,接近native。表明MPI库的选择会严重影响性能,针对特殊机器做过优化的版本最优。
PingPong Latency
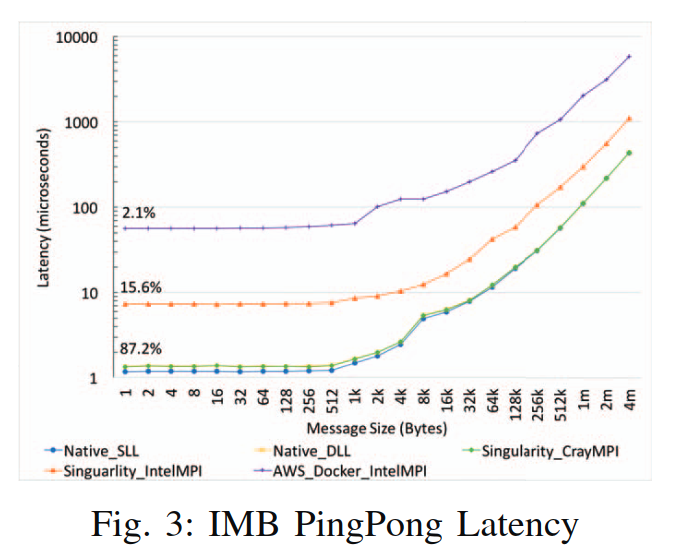
Singularity链接CrayMPI,延迟和native采用动态链接基本一致。静态链接的版本延迟最低。
HPCG
MPI程序的性能
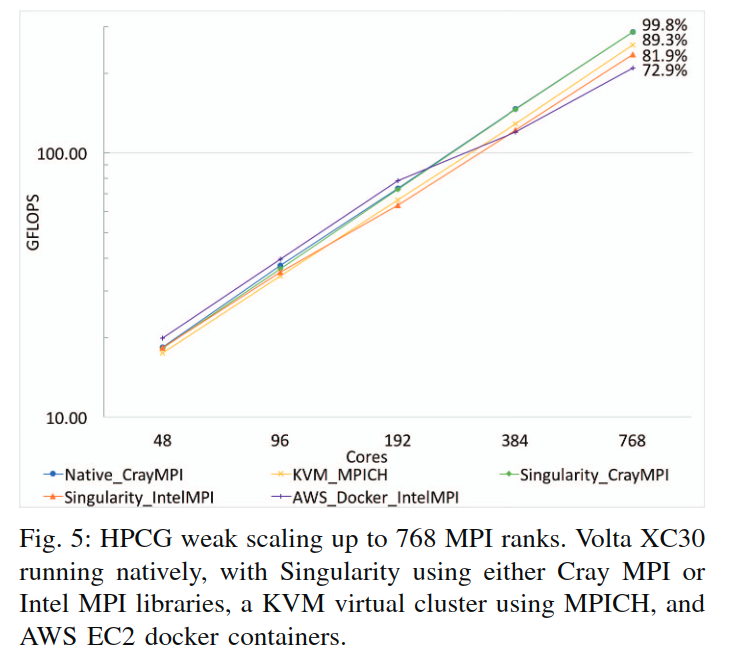
可以观察到,随着rank数量增加,Cray相比EC2的性能优势开始体现;Singularity链接CrayMPI的性能接近native;链接IntelMPI的性能甚至不如kvm虚拟机。