Performance Evaluation of Container-based Virtualization for High Performance Computing Environments
Xavier, Miguel G., et al. “Performance evaluation of container-based virtualization for high performance computing environments.” 2013 21st Euromicro International Conference on Parallel, Distributed, and Network-Based Processing. IEEE, 2013.
containers
- LXC(Linux Container) 2.0.9
- docker 17.03.0-ce, build 60ccb22
- singularity 2.2.1
singularity相比另外两款容器技术在功能上适当舍弃,比如启动不改变用户、没有使用cgroup等。这些都对性能有积极影响。
environment
CPU model Intel(R) Xeon(R) CPU E5-2683v4 @ 2.10GHz(64-core node); Memory 164 GB DDR3-1,866 MHz, 72-bit wide bus at 14.9 GB/s on P244br anda HPE Dynamic Smart Array B140i Disk; OS Ubuntu 16.04(64-bit) distribution was installed on the host machine.
benchmarks
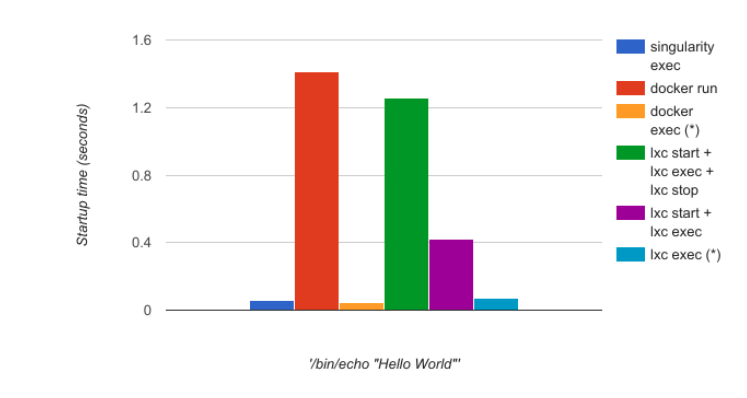
执行基本命令 echo hello world
HPL
用于测试CPU性能。编译环境:GNU C/C++ 5.4,OpenMPI 2.0.2。
For the HPL benchmark, the performance results dependon two main factors: the Basic Linear Algebra Subprogram(BLAS) library, and the problem size. We used in our experiments the GotoBLAS library, which is one of the bestportable solutions, freely available to scientists. Searchingfor the problem size that can deliver peak performance isextensive; instead, we used the same problem size 10 times(10 N, 115840 Ns) for performance analysis.
BLAS库:GotoBLAS, 问题规模:10 N, 115840 Ns
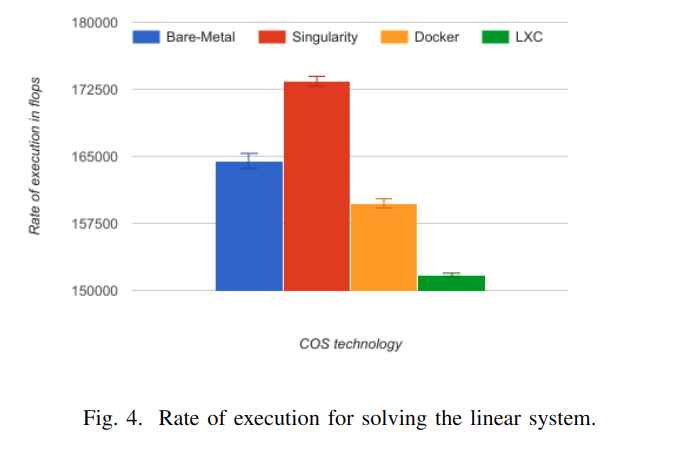
The LXC was not able to achieve native performance presenting an average overheadof 7.76%, Docker overhead was 2.89%, this could be probably caused by the default CPU use restrictions set on the daemon which by default each container is allowed to use a node’s CPU for a predefined amount of time. Singularity was able to achieve a better performance than native with 5.42% because is not emulating a full hardware level virtualization(only the mount namespace) paradigm and as the image itself is only a single metadata lookup this can yield in very high performance benefits.
TODO: singularity为什么比裸机还快?docker或者LXC通过调整cgroup的配置能否进一步释放性能?
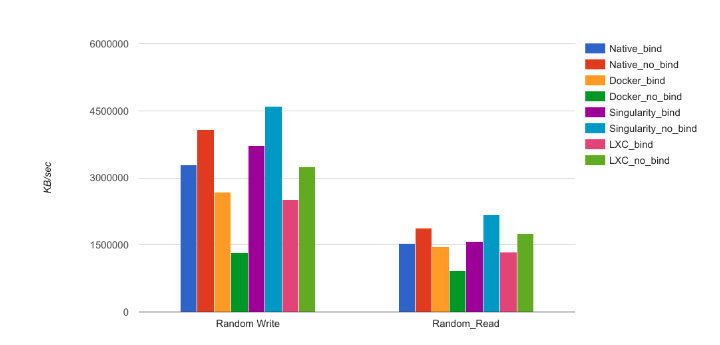
IOzone
测试IO。
We ran the benchmark witha file size of 15GB and 64KB for the record size, under two(2) scenarios. The first scenario was a totally containedfilesystem (without any bind or mount volume), and thesecond scenario was a NFS binding from the local cluster.
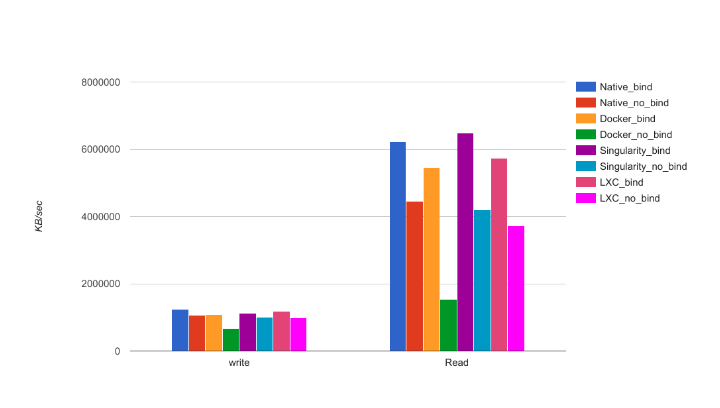
Docker advanced multi-layered unificationfilesystem (AUFS) has it drawbacks. When an applicationrunning in a container needs to write a single new value toa file on a AUFS, it must copy on write up the file from theunderlying image. The AUFS storage driver searches eachimage layer for the file. The search order is from top to bottom. When it is found, the entire file is copied up to thecontainer’s top writable layer. From there, it can be openedand modified.
Docker读写no-bind普遍比较慢的原因是AUFS。
TODO: 连续读写和随机读写时,bind和no-bind的性能优劣正好反过来。why?(猜测:可能和文件系统、挂载的硬盘有关)
STREAM
测试内存带宽。
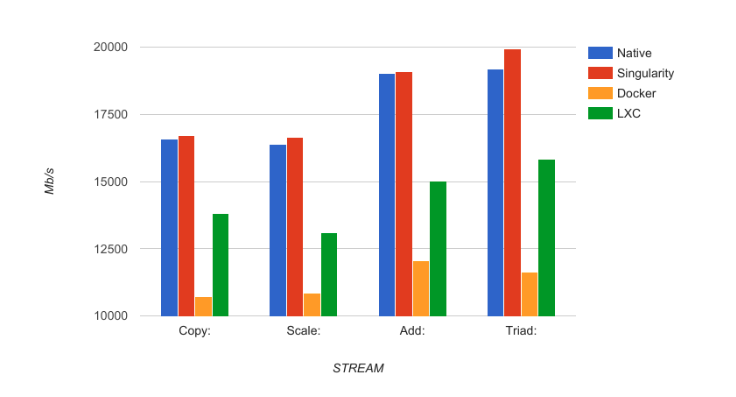
singularity性能最优,因为没有cgroup对资源的限制。
MVA-PICH OSU Micro-Benchmarks 5.3.2
测试MPI通信的带宽和延迟。
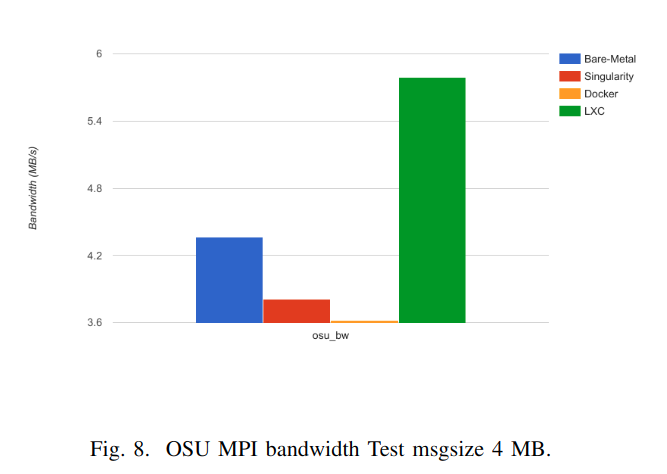
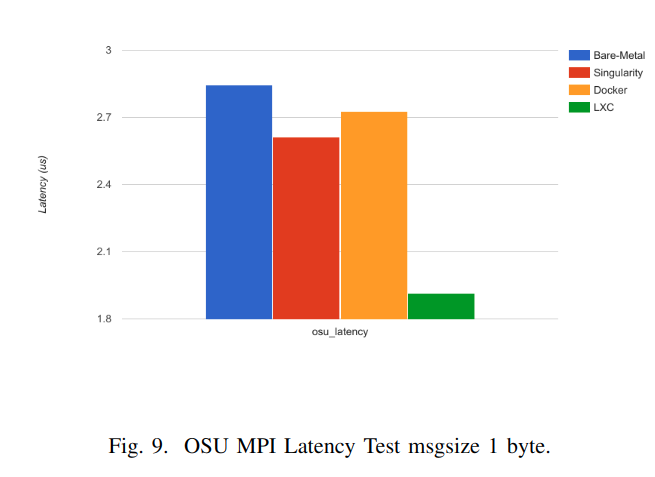
These results can be explained due to different implementations of the network isolation of the virtualization systems. While Singularity container does not implement virtualized network devices,both Docker and LXC implement network namespace that provides an entire network subsystem. COS network performance degradation is caused by the extra complexity oftransmit and receive packets (e.g. Daemon processes).
NAMD
测试GPU性能
Environment:
The performance studies were executed on a Dell Po-werEdge R720, with 2*Intel(R) Xeon(R) CPU E5-2603 @1.80GHz (8 cores) and a NVIDIA Tesla K20M.7. Froma system point of view, we used Ubuntu 16.04.2 (64-bit),with NVIDIA cuda 8.0 and the NVIDIA driver version375.26.
version:
- Singularity 2.2.1
- Docker 17.03.0-ce, build 60ccb22
- LXC 2.0.9
detail:
We ran those GPU benchmarks on a Tesla K20m with “NAMD x8664 multicoreCUDA version 2017-03-16” [on the stmv dataset (1066628 Atoms)], using the 8 cores and the GPU card, withoutany specific additional configuration, except the use of the“gpu4singularity” code for Singularity and the “nvidia-docker” tool for Docker.
result:
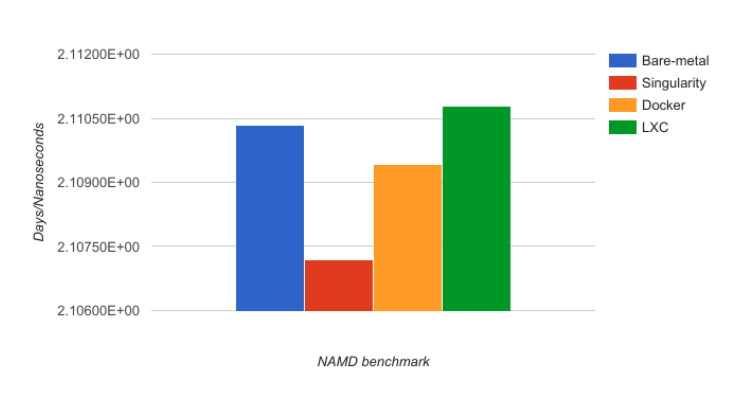
单位:天/纳秒。越低越好。
source code
作者在github上开源了测试运行的脚本。