switch (ret) { case IRQ_SET_MASK_OK: case IRQ_SET_MASK_OK_DONE: cpumask_copy(desc->irq_common_data.affinity, mask); fallthrough; case IRQ_SET_MASK_OK_NOCOPY: irq_validate_effective_affinity(data); irq_set_thread_affinity(desc); // 关键:通知中断线程 ret = 0; }
// from kernel 5.10 /* Sync real dirty inodes in upper filesystem (if it exists) */ staticintovl_sync_fs(struct super_block *sb, int wait) { structovl_fs *ofs = sb->s_fs_info; structsuper_block *upper_sb; int ret;
if (!ovl_upper_mnt(ofs)) return0;
if (!ovl_should_sync(ofs)) return0; /* * Not called for sync(2) call or an emergency sync (SB_I_SKIP_SYNC). * All the super blocks will be iterated, including upper_sb. * * If this is a syncfs(2) call, then we do need to call * sync_filesystem() on upper_sb, but enough if we do it when being * called with wait == 1. */ if (!wait) return0; // 找到upper层所在的fs upper_sb = ovl_upper_mnt(ofs)->mnt_sb;
down_read(&upper_sb->s_umount); // 执行sync, 会造成整个fs脏页回写磁盘, 耗时很长 ret = sync_filesystem(upper_sb); up_read(&upper_sb->s_umount);
/* * Show an option if * - it's set to a non-default value OR * - if the per-sb default is different from the global default */ staticint _ext4_show_options(struct seq_file *seq, struct super_block *sb, int nodefs) { structext4_sb_info *sbi = EXT4_SB(sb); structext4_super_block *es = sbi->s_es; int def_errors, def_mount_opt = sbi->s_def_mount_opt; conststructmount_opts *m; char sep = nodefs ? '\n' : ',';
// fs/ext4/ext4.h /* * Structure of the super block */ structext4_super_block { /*00*/ __le32 s_inodes_count; /* Inodes count */ __le32 s_blocks_count_lo; /* Blocks count */ __le32 s_r_blocks_count_lo; /* Reserved blocks count */ __le32 s_free_blocks_count_lo; /* Free blocks count */ /*10*/ __le32 s_free_inodes_count; /* Free inodes count */ __le32 s_first_data_block; /* First Data Block */ __le32 s_log_block_size; /* Block size */ __le32 s_log_cluster_size; /* Allocation cluster size */ /*20*/ __le32 s_blocks_per_group; /* # Blocks per group */ __le32 s_clusters_per_group; /* # Clusters per group */ __le32 s_inodes_per_group; /* # Inodes per group */ __le32 s_mtime; /* Mount time */ /*30*/ __le32 s_wtime; /* Write time */ __le16 s_mnt_count; /* Mount count */ __le16 s_max_mnt_count; /* Maximal mount count */ __le16 s_magic; /* Magic signature */ __le16 s_state; /* File system state */ __le16 s_errors; /* Behaviour when detecting errors */ __le16 s_minor_rev_level; /* minor revision level */ /*40*/ __le32 s_lastcheck; /* time of last check */ __le32 s_checkinterval; /* max. time between checks */ __le32 s_creator_os; /* OS */ __le32 s_rev_level; /* Revision level */ /*50*/ __le16 s_def_resuid; /* Default uid for reserved blocks */ __le16 s_def_resgid; /* Default gid for reserved blocks */ /* * These fields are for EXT4_DYNAMIC_REV superblocks only. * * Note: the difference between the compatible feature set and * the incompatible feature set is that if there is a bit set * in the incompatible feature set that the kernel doesn't * know about, it should refuse to mount the filesystem. * * e2fsck's requirements are more strict; if it doesn't know * about a feature in either the compatible or incompatible * feature set, it must abort and not try to meddle with * things it doesn't understand... */ __le32 s_first_ino; /* First non-reserved inode */ __le16 s_inode_size; /* size of inode structure */ __le16 s_block_group_nr; /* block group # of this superblock */ __le32 s_feature_compat; /* compatible feature set */ /*60*/ __le32 s_feature_incompat; /* incompatible feature set */ __le32 s_feature_ro_compat; /* readonly-compatible feature set */ /*68*/ __u8 s_uuid[16]; /* 128-bit uuid for volume */ /*78*/char s_volume_name[EXT4_LABEL_MAX]; /* volume name */ /*88*/char s_last_mounted[64] __nonstring; /* directory where last mounted */ /*C8*/ __le32 s_algorithm_usage_bitmap; /* For compression */ /* * Performance hints. Directory preallocation should only * happen if the EXT4_FEATURE_COMPAT_DIR_PREALLOC flag is on. */ __u8 s_prealloc_blocks; /* Nr of blocks to try to preallocate*/ __u8 s_prealloc_dir_blocks; /* Nr to preallocate for dirs */ __le16 s_reserved_gdt_blocks; /* Per group desc for online growth */ /* * Journaling support valid if EXT4_FEATURE_COMPAT_HAS_JOURNAL set. */ /*D0*/ __u8 s_journal_uuid[16]; /* uuid of journal superblock */ /*E0*/ __le32 s_journal_inum; /* inode number of journal file */ __le32 s_journal_dev; /* device number of journal file */ __le32 s_last_orphan; /* start of list of inodes to delete */ __le32 s_hash_seed[4]; /* HTREE hash seed */ __u8 s_def_hash_version; /* Default hash version to use */ __u8 s_jnl_backup_type; __le16 s_desc_size; /* size of group descriptor */ /*100*/ __le32 s_default_mount_opts; __le32 s_first_meta_bg; /* First metablock block group */ __le32 s_mkfs_time; /* When the filesystem was created */ __le32 s_jnl_blocks[17]; /* Backup of the journal inode */ /* 64bit support valid if EXT4_FEATURE_COMPAT_64BIT */ /*150*/ __le32 s_blocks_count_hi; /* Blocks count */ __le32 s_r_blocks_count_hi; /* Reserved blocks count */ __le32 s_free_blocks_count_hi; /* Free blocks count */ __le16 s_min_extra_isize; /* All inodes have at least # bytes */ __le16 s_want_extra_isize; /* New inodes should reserve # bytes */ __le32 s_flags; /* Miscellaneous flags */ __le16 s_raid_stride; /* RAID stride */ __le16 s_mmp_update_interval; /* # seconds to wait in MMP checking */ __le64 s_mmp_block; /* Block for multi-mount protection */ __le32 s_raid_stripe_width; /* blocks on all data disks (N*stride)*/ __u8 s_log_groups_per_flex; /* FLEX_BG group size */ __u8 s_checksum_type; /* metadata checksum algorithm used */ __u8 s_encryption_level; /* versioning level for encryption */ __u8 s_reserved_pad; /* Padding to next 32bits */ __le64 s_kbytes_written; /* nr of lifetime kilobytes written */ __le32 s_snapshot_inum; /* Inode number of active snapshot */ __le32 s_snapshot_id; /* sequential ID of active snapshot */ __le64 s_snapshot_r_blocks_count; /* reserved blocks for active snapshot's future use */ __le32 s_snapshot_list; /* inode number of the head of the on-disk snapshot list */ #define EXT4_S_ERR_START offsetof(struct ext4_super_block, s_error_count) __le32 s_error_count; /* number of fs errors */ __le32 s_first_error_time; /* first time an error happened */ __le32 s_first_error_ino; /* inode involved in first error */ __le64 s_first_error_block; /* block involved of first error */ __u8 s_first_error_func[32] __nonstring; /* function where the error happened */ __le32 s_first_error_line; /* line number where error happened */ __le32 s_last_error_time; /* most recent time of an error */ __le32 s_last_error_ino; /* inode involved in last error */ __le32 s_last_error_line; /* line number where error happened */ __le64 s_last_error_block; /* block involved of last error */ __u8 s_last_error_func[32] __nonstring; /* function where the error happened */ #define EXT4_S_ERR_END offsetof(struct ext4_super_block, s_mount_opts) __u8 s_mount_opts[64]; __le32 s_usr_quota_inum; /* inode for tracking user quota */ __le32 s_grp_quota_inum; /* inode for tracking group quota */ __le32 s_overhead_clusters; /* overhead blocks/clusters in fs */ __le32 s_backup_bgs[2]; /* groups with sparse_super2 SBs */ __u8 s_encrypt_algos[4]; /* Encryption algorithms in use */ __u8 s_encrypt_pw_salt[16]; /* Salt used for string2key algorithm */ __le32 s_lpf_ino; /* Location of the lost+found inode */ __le32 s_prj_quota_inum; /* inode for tracking project quota */ __le32 s_checksum_seed; /* crc32c(uuid) if csum_seed set */ __u8 s_wtime_hi; __u8 s_mtime_hi; __u8 s_mkfs_time_hi; __u8 s_lastcheck_hi; __u8 s_first_error_time_hi; __u8 s_last_error_time_hi; __u8 s_first_error_errcode; __u8 s_last_error_errcode; __le16 s_encoding; /* Filename charset encoding */ __le16 s_encoding_flags; /* Filename charset encoding flags */ __le32 s_orphan_file_inum; /* Inode for tracking orphan inodes */ __le32 s_reserved[94]; /* Padding to the end of the block */ __le32 s_checksum; /* crc32c(superblock) */ };
它会有个字段s_default_mount_opts,其实就是tune2fs工具展示的Default mount options,这个值是在磁盘上永久保存的,一般都是当mkfs创建文件系统的时候写入,也可以通过tune2fs工具来修改。
/* Set defaults before we parse the mount options */ def_mount_opts = le32_to_cpu(es->s_default_mount_opts); set_opt(sb, INIT_INODE_TABLE); if (def_mount_opts & EXT4_DEFM_DEBUG) set_opt(sb, DEBUG); if (def_mount_opts & EXT4_DEFM_BSDGROUPS) set_opt(sb, GRPID); if (def_mount_opts & EXT4_DEFM_UID16) set_opt(sb, NO_UID32); /* xattr user namespace & acls are now defaulted on */ set_opt(sb, XATTR_USER); #ifdef CONFIG_EXT4_FS_POSIX_ACL set_opt(sb, POSIX_ACL); #endif if (ext4_has_feature_fast_commit(sb)) set_opt2(sb, JOURNAL_FAST_COMMIT); /* don't forget to enable journal_csum when metadata_csum is enabled. */ if (ext4_has_metadata_csum(sb)) set_opt(sb, JOURNAL_CHECKSUM);
if (le16_to_cpu(es->s_errors) == EXT4_ERRORS_PANIC) set_opt(sb, ERRORS_PANIC); elseif (le16_to_cpu(es->s_errors) == EXT4_ERRORS_CONTINUE) set_opt(sb, ERRORS_CONT); else set_opt(sb, ERRORS_RO); /* block_validity enabled by default; disable with noblock_validity */ set_opt(sb, BLOCK_VALIDITY); if (def_mount_opts & EXT4_DEFM_DISCARD) set_opt(sb, DISCARD);
if ((def_mount_opts & EXT4_DEFM_NOBARRIER) == 0) set_opt(sb, BARRIER);
/* * enable delayed allocation by default * Use -o nodelalloc to turn it off */ if (!IS_EXT3_SB(sb) && !IS_EXT2_SB(sb) && ((def_mount_opts & EXT4_DEFM_NODELALLOC) == 0)) set_opt(sb, DELALLOC);
if (sb->s_blocksize == PAGE_SIZE) set_opt(sb, DIOREAD_NOLOCK); }
/* We have now updated the journal if required, so we can * validate the data journaling mode. */ switch (test_opt(sb, DATA_FLAGS)) { case0: /* No mode set, assume a default based on the journal * capabilities: ORDERED_DATA if the journal can * cope, else JOURNAL_DATA */ if (jbd2_journal_check_available_features (sbi->s_journal, 0, 0, JBD2_FEATURE_INCOMPAT_REVOKE)) { set_opt(sb, ORDERED_DATA); sbi->s_def_mount_opt |= EXT4_MOUNT_ORDERED_DATA; } else { set_opt(sb, JOURNAL_DATA); sbi->s_def_mount_opt |= EXT4_MOUNT_JOURNAL_DATA; } break; case EXT4_MOUNT_ORDERED_DATA: case EXT4_MOUNT_WRITEBACK_DATA: // ... } // ... }
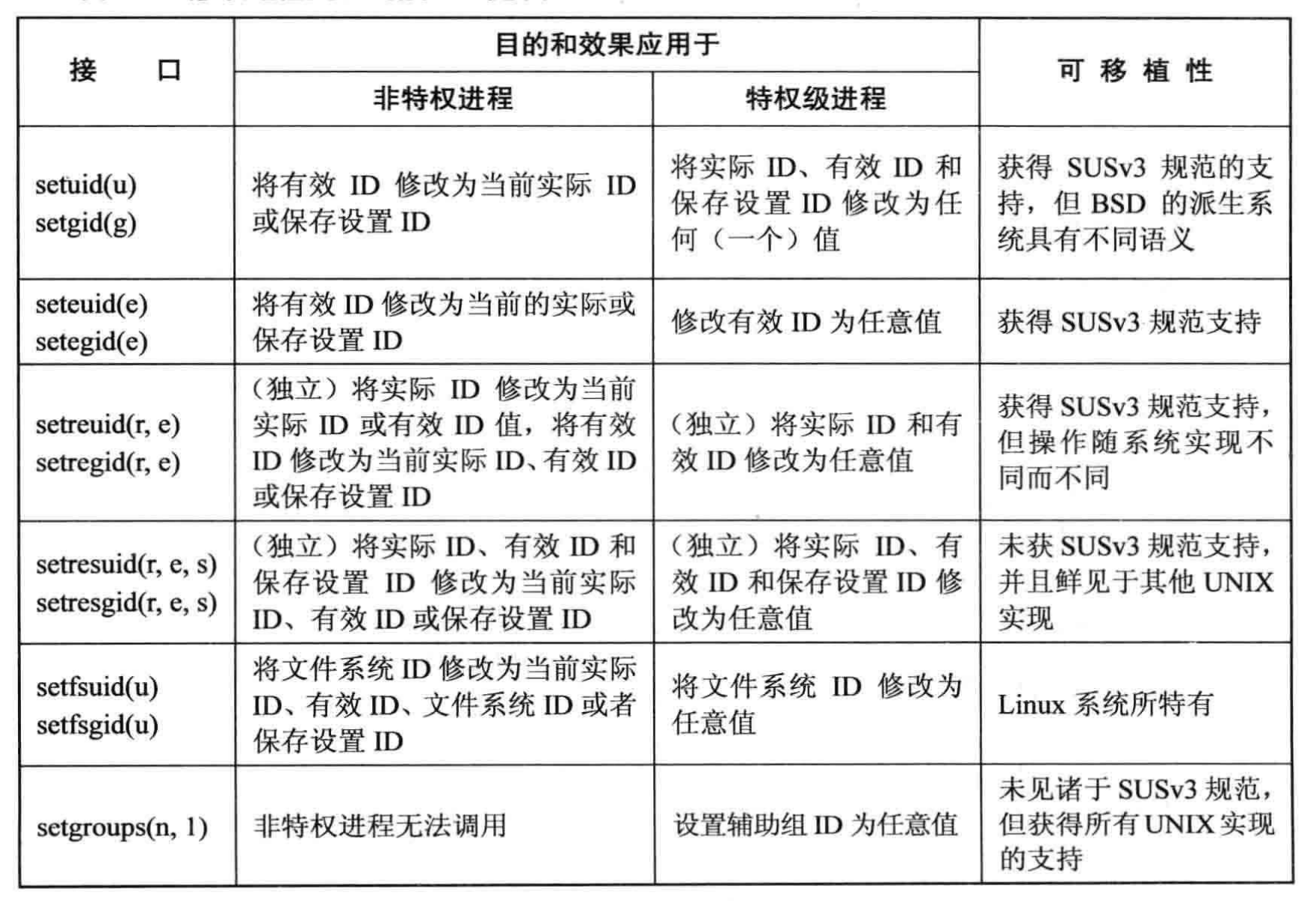
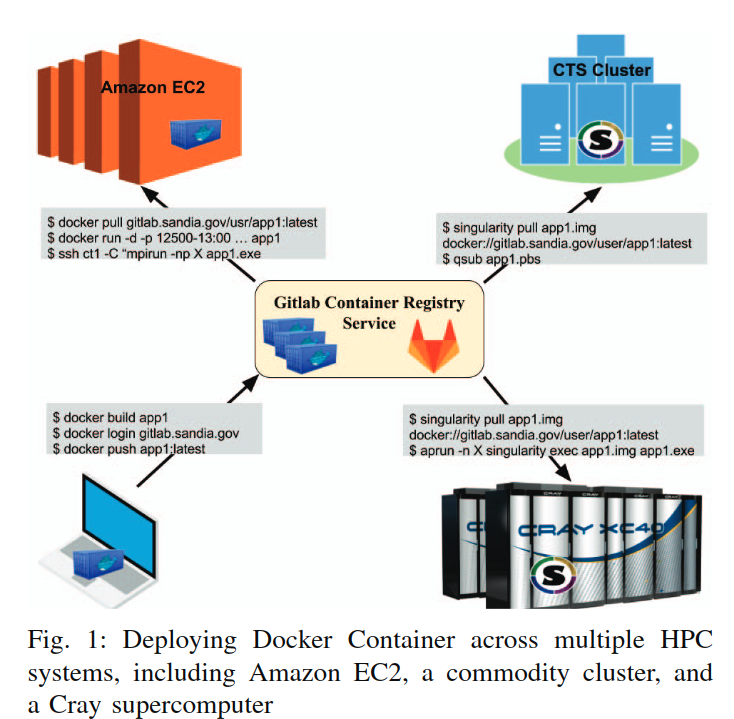
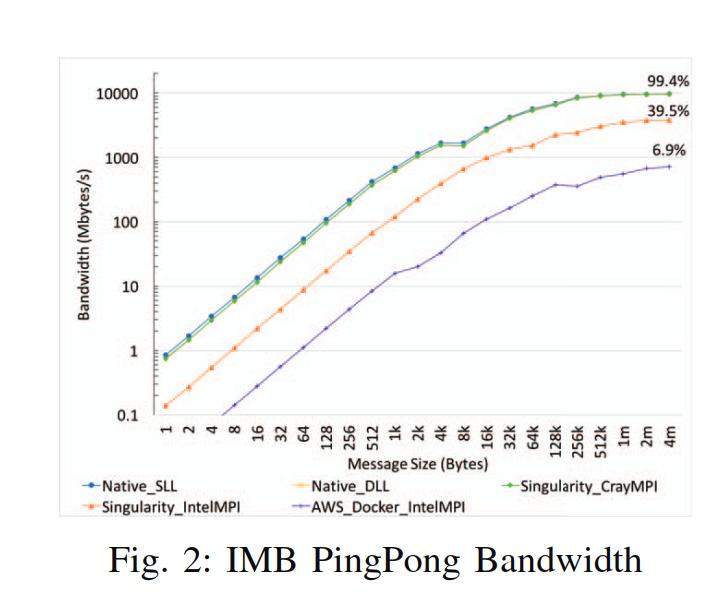
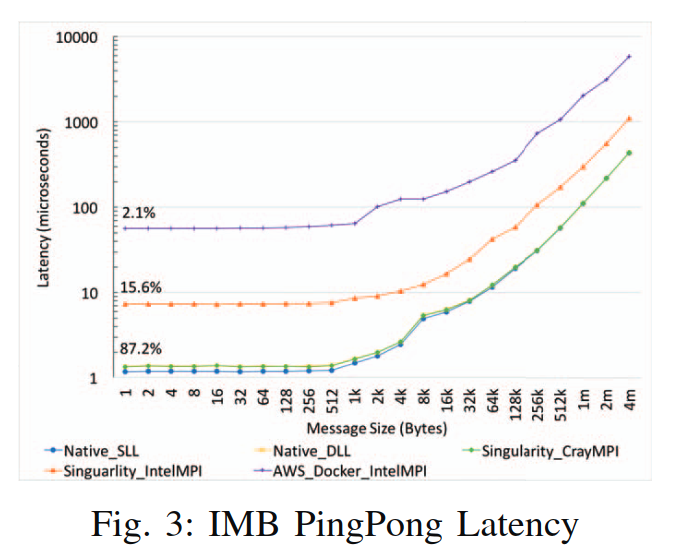
Younge, Andrew J., et al. “A tale of two systems: Using containers to deploy HPC applications on supercomputers and clouds.” 2017 IEEE International Conference on Cloud Computing Technology and Science (CloudCom). IEEE, 2017.
base image: Centos 7, both benchmarks were built using the Intel 2017 Parallel Studio, which includes the latest Intel compilers and Intel MPI library.
拉取镜像:
1
docker pull ajyounge/hpcg-container
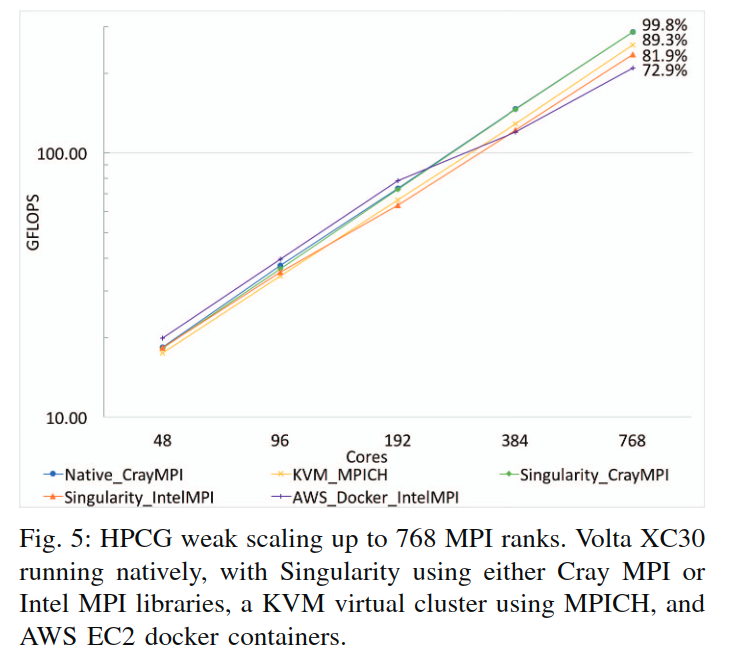
Cray XC30 supercomputing platform
hardware:
Volta includes 56 compute nodes packaged in a single enclosure, with each node consisting of two Intel Ivy Bridge E5-2695v2 2.4 GHz processors (24 cores total), 64GB of memory, and a Cray Aries network interface.
shared file system
Shared file system supportis provided by NFS I/O servers projected to compute nodes via Cray’s proprietary DVS storage infrastructure.
OS:Cray Compute Node Linux (CNL ver. 5.2.UP04, 基于SUSE Linux 11), linux kernel v3.0.101
Specifically, we configure Singularity to mount /opt/cray, as well as /var/opt/cray for each container instance.
In order to leverage the Aries interconnect as well as advanced shared memory intra-node communication mechanisms, we dynamically link Cray’s MPI and associated libraries provided in /opt/cray directly within the container
Xavier, Miguel G., et al. “Performance evaluation of container-based virtualization for high performance computing environments.” 2013 21st Euromicro International Conference on Parallel, Distributed, and Network-Based Processing. IEEE, 2013.
CPU model Intel(R) Xeon(R) CPU E5-2683v4 @ 2.10GHz(64-core node); Memory 164 GB DDR3-1,866 MHz, 72-bit wide bus at 14.9 GB/s on P244br anda HPE Dynamic Smart Array B140i Disk; OS Ubuntu 16.04(64-bit) distribution was installed on the host machine.
benchmarks
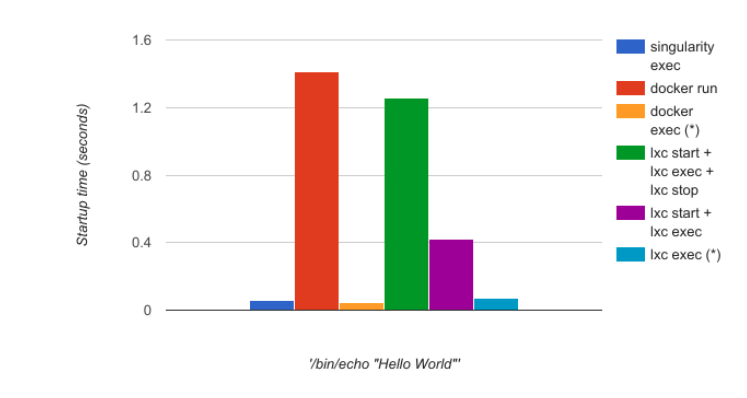
执行基本命令 echo hello world
HPL
用于测试CPU性能。编译环境:GNU C/C++ 5.4,OpenMPI 2.0.2。
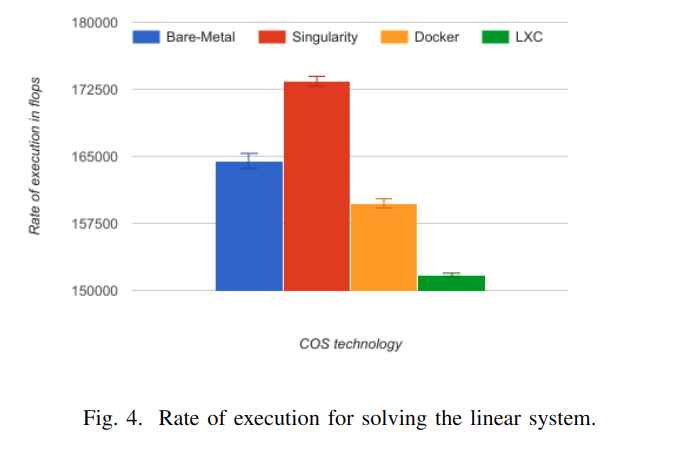
For the HPL benchmark, the performance results dependon two main factors: the Basic Linear Algebra Subprogram(BLAS) library, and the problem size. We used in our experiments the GotoBLAS library, which is one of the bestportable solutions, freely available to scientists. Searchingfor the problem size that can deliver peak performance isextensive; instead, we used the same problem size 10 times(10 N, 115840 Ns) for performance analysis.
BLAS库:GotoBLAS, 问题规模:10 N, 115840 Ns
The LXC was not able to achieve native performance presenting an average overheadof 7.76%, Docker overhead was 2.89%, this could be probably caused by the default CPU use restrictions set on the daemon which by default each container is allowed to use a node’s CPU for a predefined amount of time. Singularity was able to achieve a better performance than native with 5.42% because is not emulating a full hardware level virtualization(only the mount namespace) paradigm and as the image itself is only a single metadata lookup this can yield in very high performance benefits.
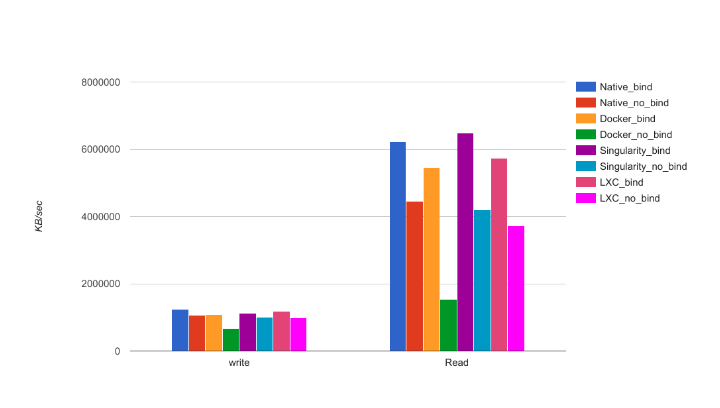
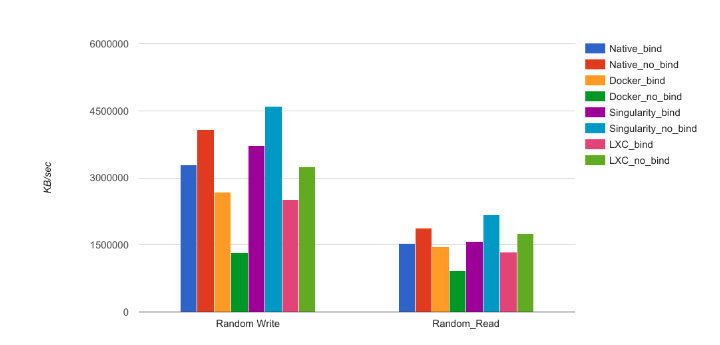
We ran the benchmark witha file size of 15GB and 64KB for the record size, under two(2) scenarios. The first scenario was a totally containedfilesystem (without any bind or mount volume), and thesecond scenario was a NFS binding from the local cluster.
Docker advanced multi-layered unificationfilesystem (AUFS) has it drawbacks. When an applicationrunning in a container needs to write a single new value toa file on a AUFS, it must copy on write up the file from theunderlying image. The AUFS storage driver searches eachimage layer for the file. The search order is from top to bottom. When it is found, the entire file is copied up to thecontainer’s top writable layer. From there, it can be openedand modified.
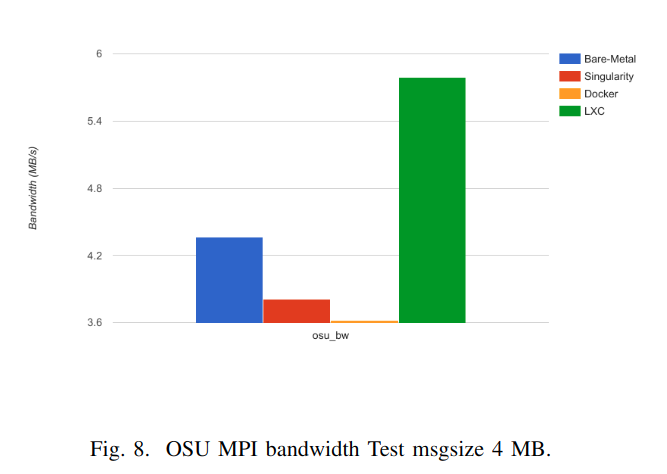
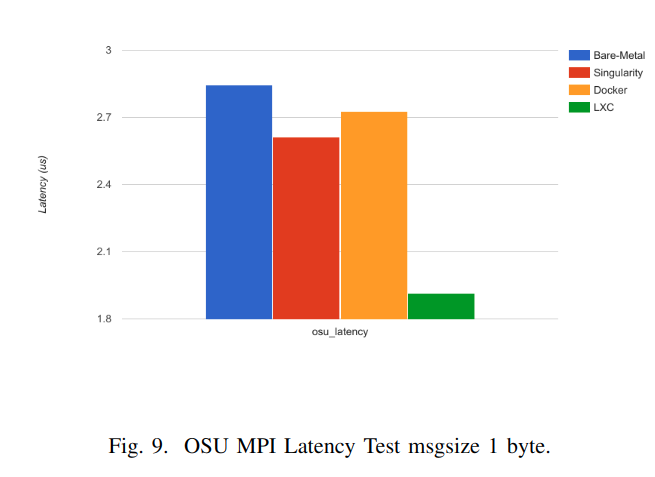
These results can be explained due to different implementations of the network isolation of the virtualization systems. While Singularity container does not implement virtualized network devices,both Docker and LXC implement network namespace that provides an entire network subsystem. COS network performance degradation is caused by the extra complexity oftransmit and receive packets (e.g. Daemon processes).
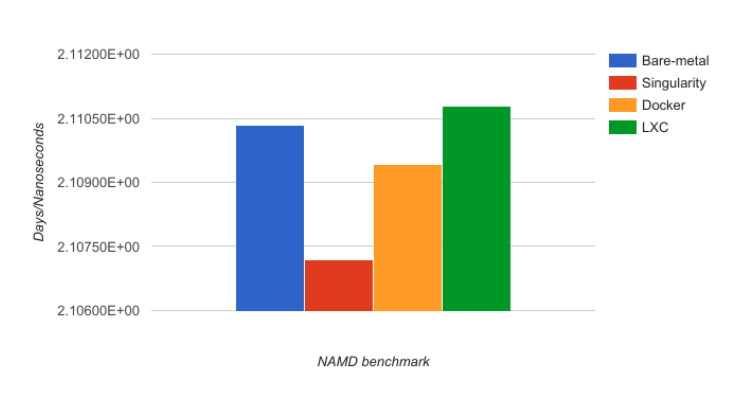
NAMD
测试GPU性能
Environment:
The performance studies were executed on a Dell Po-werEdge R720, with 2*Intel(R) Xeon(R) CPU E5-2603 @1.80GHz (8 cores) and a NVIDIA Tesla K20M.7. Froma system point of view, we used Ubuntu 16.04.2 (64-bit),with NVIDIA cuda 8.0 and the NVIDIA driver version375.26.
version:
Singularity 2.2.1
Docker 17.03.0-ce, build 60ccb22
LXC 2.0.9
detail:
We ran those GPU benchmarks on a Tesla K20m with “NAMD x8664 multicoreCUDA version 2017-03-16” [on the stmv dataset (1066628 Atoms)], using the 8 cores and the GPU card, withoutany specific additional configuration, except the use of the“gpu4singularity” code for Singularity and the “nvidia-docker” tool for Docker.
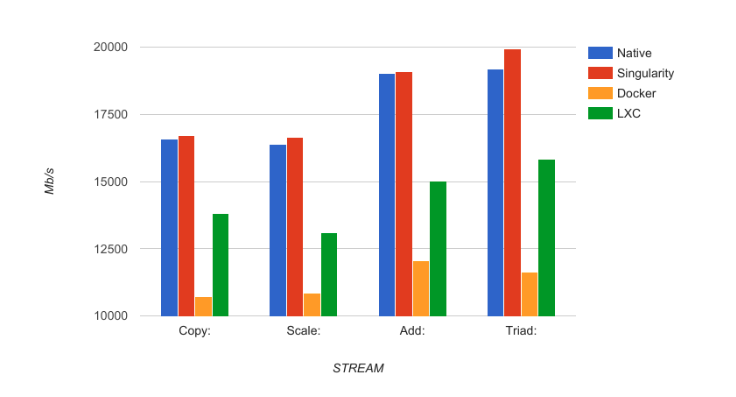
We compiled with STREAM_ARRAY_SIZE set to 2 billion to match the recommended 4× cache and pinned the process to a semi-arbitrary core using the Slurm argument –cpu_bind=v,core,map_cpu:23.
4个环境下测试出的带宽几乎相同
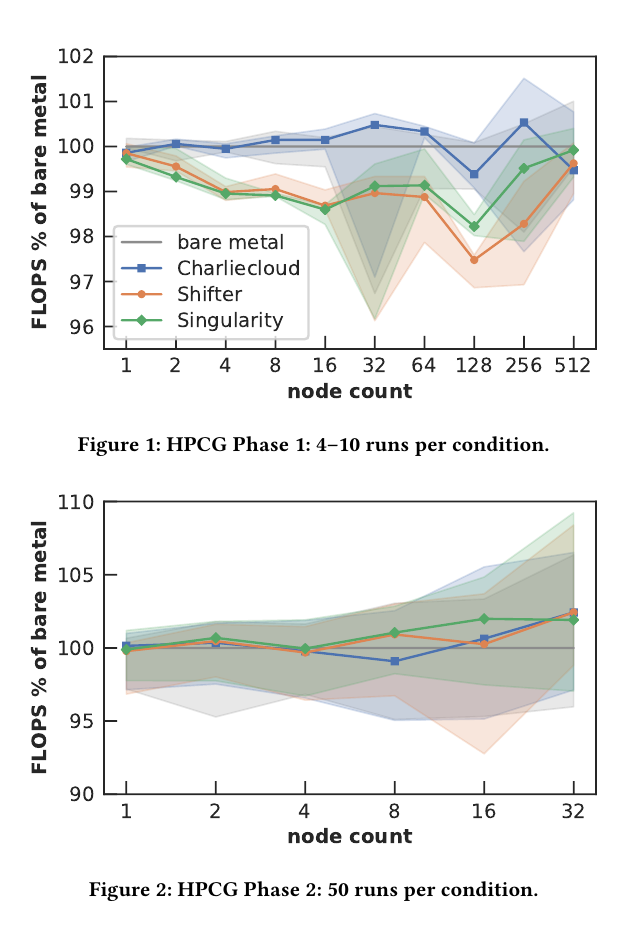
HPCG(High Performance Conjugate Gradients)
We used a cube dimension of 104 and a run time of 60 seconds, all 36 cores per node, one MPI rank per core, and one thread per rank.
memory usage
To understand node memory usage with STREAM, we computed MemTotal – MemFree from /proc/meminfo, sampled at 10-second intervals.
Bare metal total node usage was a median of 50.8 MiB. Charliecloud added 1200 MiB, Shifter 16 MiB, and Singularity 37 MiB.
Charliecloudn内存使用多可能是因为存储在tmpfs里的1.2Gib镜像。
For HPCG, we sampled at 10-second intervals the writeable/private field of pmap(1), which reports memory consumption of individual processes. Median memory usage for all three container technologies is, to two significant figures, 0.64% lower than bare metal at 1 node, 0.53% lower at 8 nodes, 0.53–0.54% lower at 64 nodes, and 1.2% higher at 512 nodes, a minimal difference.
Itanium C++ ABI是一个用于C++的ABI。作为ABI,它给出了实现该语言的精确规则,确保程序中单独编译的部分能够成功地互操作。尽管它最初是为Itanium架构开发的,但它不是特定于平台的,可以在任意的C ABI之上进行分层移植。因此,它被用作所有主要架构上的许多主要操作系统的标准C++ ABI,并在许多主要的c++编译器中实现,包括GCC和Clang。
简单点来说,x64的Linux上,GCC和Clang都是遵循Itanium C++ ABI的。所以今天就针对这个它来探讨一下member pointer的实现。
pointer to data member
A pointer to data member is an offset from the base address of the class object containing it, represented as a ptrdiff_t. It has the size and alignment attributes of a ptrdiff_t. A NULL pointer is represented as -1.
A pointer to member function is a pair as follows:
ptr:
For a non-virtual function, this field is a simple function pointer. (Under current base Itanium psABI conventions, that is a pointer to a GP/function address pair.) For a virtual function, it is 1 plus the virtual table offset (in bytes) of the function, represented as a ptrdiff_t. The value zero represents a NULL pointer, independent of the adjustment field value below.
adj:
The required adjustment to this, represented as a ptrdiff_t.
s = pthread_mutex_unlock(&thread_mutex); if (s != 0) errExitEN(s, "pthread_mutex_unlock");
s = pthread_cond_signal(&thread_died); if (s != 0) errExitEN(s, "pthread_cond_signal");
returnNULL; }
intmain(int argc, char *argv[]) { int s, idx;
thread = calloc(argc - 1, sizeof(*thread)); if (thread == NULL) errExit("calloc"); for (idx = 0; idx < argc-1; ++idx) { thread[idx].sleep_time = getInt(argv[idx+1], GN_NONNEG, NULL); thread[idx].state = TS_ALIVE; s = pthread_create(&thread[idx].tid, NULL, thread_func, &idx); if (s != 0) errExitEN(s, "pthread_create"); }
tot_threads = argc - 1; num_live = tot_threads;
while (num_live > 0) { s = pthread_mutex_lock(&thread_mutex); if (s != 0) errExitEN(s, "pthread_mutex_lock");
while (num_unjoined == 0) { s = pthread_cond_wait(&thread_died, &thread_mutex); if (s != 0) errExitEN(s, "pthread_cond_wait"); }
for (idx = 0; idx < tot_threads; ++idx) { if (thread[idx].state == TS_TERMINATED) { s = pthread_join(thread[idx].tid, NULL); if (s != 0) errExitEN(s, "pthread_join");
Any integer can be cast to any pointer type. Except for the null pointer constants such as NULL (which doesn’t need a cast), the result is implementation-defined, may not be correctly aligned, may not point to an object of the referenced type, and may be a trap representation.
Any pointer type can be cast to any integer type. The result is implementation-defined, even for null pointer values (they do not necessarily result in the value zero). If the result cannot be represented in the target type, the behavior is undefined (unsigned integers do not implement modulo arithmetic on a cast from pointer)